Google Correlate alternative: Similiarity search of Wikipedia Pageview Statistics in Python
Google Correlate has been deprecated since years, now you can build your own successor with the power of open data.

What is Google Correlate?
If you remember the stone age of the internet, there was a tool similar to Google Trends but for finding correlated search patterns. You can see in the video below, how each search term would be correlated. Its mechanism was even able to predict flu trends for a period of time. Google’s white paper explains how it’s done at scale. Alphabet being Alphabet of course shut down the tool in 2019. So let’s build our own with the power of open data.
What is an alternative to Google Correlate?
There is no real alternative since no one has as much search data like Google. But with a bit of creativity you can build your own in a weekend project. The idea builds on the previous post for trend prediction using Wikipedia views to see for example the demand for political parties.
In the following steps we can achieve similar results:
Scrape Wikipedia page views
Transform data into a pivot table (columns = title, y = views per day)
Use similarity search to find correlated articles
How to correlate historic Wikipedia data?
We can think of the time series data (X page, Y clicks per day) as a vector. We want to find the closest vector according to for example ‘Cosine distance’ metric. Python provides simple tooling for this with scikit-learn.
Loading the data with polars:
import polars as pl
# Using the data from the previous post
hourly_views = pl.read_parquet(
"export/*.parquet"
).pivot(on="column_2",index="filename",values="column_5",aggregate_function='sum')
columns = hourly_views.columns[1:]
search_index = columns.tolist().index("Nvidia_Tesla")
data = hourly_views.to_numpy()[1:].T
query = data[search_index-1:search_index]Now we have our dataset we can use similarity search. To understand how nearest neighbors works I can recommend the explanation by statquest:
Now let’s do it Python. We store our vector for ‘Nvidia’ in query and perform the nearest_neighbor search across our fitted data:
from sklearn.neighbors import NearestNeighbors
nn = NearestNeighbors(n_neighbors=25, algorithm='auto',metric='cosine')
nn.fit(data)
distances, indices = nn.kneighbors(query.reshape(1,-1), n_neighbors=50)Results: Similar Pageview patterns for Nvidia:
Let’s use the indices on our columns to see the most closest articles for Nvidia Tesla
>> columns[indices]
[['Nvidia_Tesla' 'Information_security' 'Redlining' 'Северсталь'
'Law_of_large_numbers' 'Gamma_function' 'Proportionality_(mathematics)'
'Tensor_Processing_Unit' 'ChatGPT' 'Dimethyl_sulfoxide'
"Euler's_formula" 'Electrocardiography' 'Klebsiella' 'Waterfall_model'
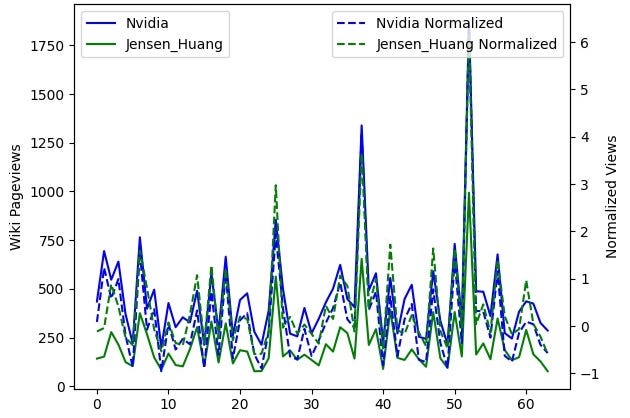
'Matrix_multiplication',...]]Results of correlating Wikipedia page views:
Now the same for hourly Wikipedia views. Based on the euclidian distance it’s Jensen Huang the founder of Nvidia.